Embedding Model 訓練與微調
基本介紹
模型本質: Embedding Model(如 sentence-transformers)是基於 Transformer 架構的深度神經網路。
機制:Self-Attention (自我注意力)
透過 Query (Q), Key (K), Value (V) 的矩陣運算,讓模型在處理某個字時,會自動「注意」句子中其他相關的字。
效果: 捕捉上下文語意。例如能區分「蘋果」在「蘋果好甜」與「蘋果股價」中完全不同的語意特徵。
輸出: 將非結構化的文字,投射成高維空間中的一個座標(向量)。
利用此種具有 Transformer 架構的模型進行為微調的原因在於,相較於傳統模型(如 Word2Vec, GloVe)每個詞的向量是固定的。不管「蘋果」是在講水果還是手機,它的向量都一模一樣。這就像是一本死板的字典。
補充:
- 輸入轉化: Input Text → Tokens → Initial Vectors (Embedding 層)。
- 三權分立 (Q, K, V):每個向量透過學到的權重矩陣 $W^Q, W^K, W^V$ 映射出三個身份:Query ($q$): 「我」在找什麼資訊?Key ($k$): 「我」能提供什麼資訊?Value ($v$): 「我」實際代表的資訊內容。
- 計算關聯 (Attention Score):拿當前詞的 $q$,去跟全句所有詞的 $k$ 做點積 ($q \cdot k$),得到原始分數 $a$。Scale & Softmax: 將 $a$ 除以 $\sqrt{d_k}$(縮放防止數值過大)並過 Softmax,得到標準化權重 $a’$(加總為 1)。
- 語意融合 (Output):將所有詞的 $v$ 乘以對應的 $a’$ 後全部加總,得到包含上下文資訊的新向量 $b$。結果: $b$ 不再是孤立的單字,而是吸收了全句精華的「動態語意特徵」。
「Embedding 模型通常包含多層 Transformer 堆疊。每經過一次 Self-attention 運算,模型都能更深層地萃取輸入語句中各詞彙間的關聯。隨層數增加,模型從理解基礎語法進化到掌握抽象語意,最終產出具備高度上下文感知(Context-aware)的細膩向量,大幅提升了搜尋與匹配的精準度。」
BERT 模型
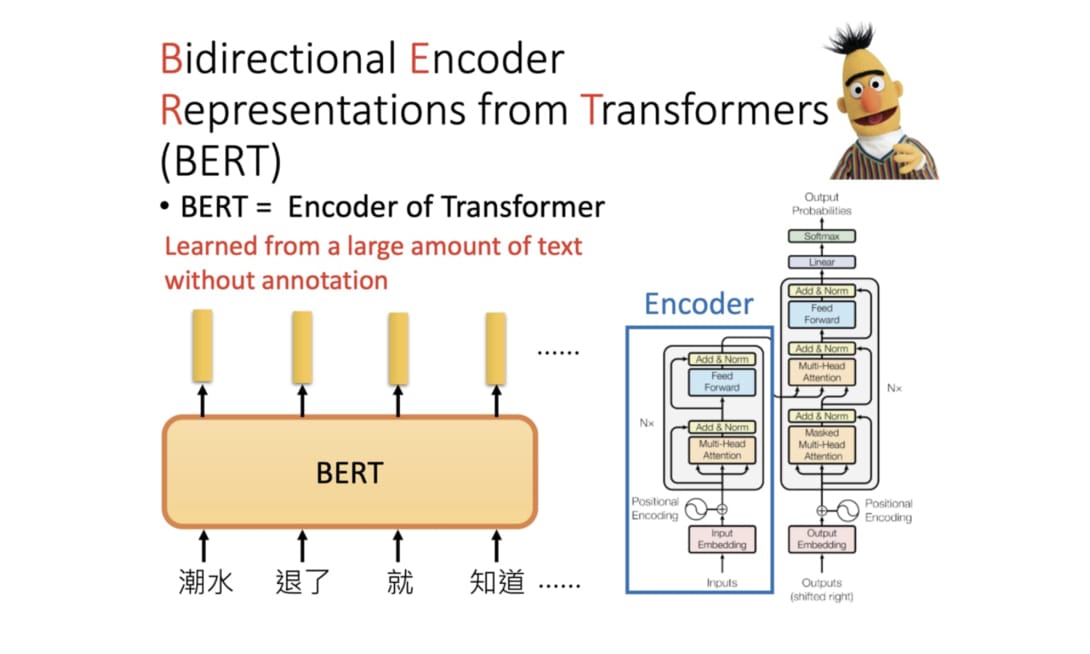
BERT (Bidirectional Encoder Representations from Transformers) 模型,Bidirectional Encoder,表示雙向編碼,和大語言模型的 transformer 架構的差異在此,這種模型並不需要產出文字或其他內容,單純只是把輸入向量化,所以模型的 self-attention 機制是會把輸入的所有內容都看過的,不像大語言模型會有 masking 的機制(限制模型只能看到輸入中左邊的內容)
單層 Transformer 處理流程:
Multi-Head Attention: 將 $X_n$ 透過 $W^Q, W^K, W^V$ 矩陣轉化為大量 $q, k, v$。
計算: 每個字主動對全句進行 Self-Attention 權重分配與加權總和。
目的: 讓每個字吸收「上下文」資訊(例如:知道「蘋果」在此處是指「公司」)。產出: 上下文特徵向量 $Z_{attn}$。
第一次融合與穩定 (Add & Norm):
- Add (殘差連接): 將 $Z_{attn}$ 與原始輸入 $X_n$ 進行向量加法($Z_{attn} + X_n$)。
- Norm (層正規化): 對相加後的結果進行標準化,確保數值穩定。目的: 保留原始資訊,防止語義在深層網路中失真。
深度思考 (Feed Forward Network)動作: 將上一步的結果送入兩層全連接神經網路(通常會先放大維度再縮小)。
- 計算: 進行非線性轉換(使用 ReLU 或 GeLU 激活函數)。
- 目的: 對 Attention 抓到的關係進行深層分析與特徵昇華(儲存領域知識)。
- 產出: 深度加工向量 $Z_{ffn}$。
第二次融合與穩定 (Add & Norm)Add (殘差連接): 將 $Z_{ffn}$ 與進入第三步前的輸入進行向量加法。
- Norm (層正規化): 再次進行標準化,平滑數值分佈。
- 目的: 確保深度加工後的資訊能穩定傳遞給下一層。
輸出 (Output)結果: 產出這一層的最終向量 $X_{n+1}$。下一步: 這個 $X_{n+1}$ 會直接作為 第 $n+1$ 層 的輸入,重複以上流程。
模型微調的資料格式
微調 Embedding 模型時,不能只給模型看一句話。要給它一組關係,「三元組」(Triplet)
Anchor (錨點): 使用者的問題(例如:「台積電股價表現?」)。
Positive (正樣本): 正確或相關的內容(例如:「台積電今日收盤價創新高」)。
Negative (負樣本): 錯誤或無關的內容(例如:「如何在家烤蘋果派」)。
Hard Negative (困難負樣本):跟正解有點關聯,但實際上是錯誤的內容。 (強迫模型進入 Transformer 的深層 進行非線性轉換,去辨識微小的語意差異。這能顯著提升 MRR(正確答案的排名會更前面)。)
目標: 透過訓練,讓模型內部的 Transformer 權重 發生變化,使得 $Anchor$ 與 $Positive$ 的向量距離拉近,而與 $Negative$ 的距離拉遠。
損失函數:目前較主流為 Multiple Negatives Ranking Loss (MNRL)
概念:假設一個 Batch 有 64 組 $(A, P)$ 配對。對於第 1 個問句($A_1$),除了它自己的正確答案 $P_1$ 之外,Batch 內其他的 63 個正確答案($P_2$ 到 $P_{64}$)都會自動變成它的「負樣本」。
效果: 一次運算,模型就像是在考一題「64 選 1」的超難選擇題,學習效率極高。
所以不需要費心手動建置許多負樣本,MNRL 可以將批次內除了正確解答的樣本都當成錯誤樣本。
公式:
$$L_i = -\log \frac{e^{\text{sim}(a_i, p_i) / \tau}}{\sum e^{\text{sim}(a_i, p_j) / \tau}}$$- 分子:正確答案的相似度。模型想讓它越高越好。
- 分母:所有候選答案(包含一堆負樣本)的相似度總和。
核心目標:極大化正確答案在全體候選人中的「佔比」。 作法:MNRL 核心是一個「矩陣乘法」加上 Cross Entropy(交叉熵):
矩陣計算: 把所有的 $Anchor$ 向量跟所有的 $Positive$ 向量做點積(相似度計算)。
期望結果: 對角線上的分數(自己對應的正確答案)應該最高,非對角線(別人的答案)應該極低。
優化: 模型會瘋狂調整 Transformer 權重,讓對角線的分數越來越大,其餘的分數被壓到趨近於零。
若是加入了 Hard Negative 樣本,則損失函數之公式分母將改為
$$\sum e^{\text{sim}(a_i, \text{正樣本})} + e^{\text{sim}(a_i, \text{硬負樣本})} + \sum e^{\text{sim}(a_i, \text{Batch內其他樣本})}$$Hard Negative 樣本與 Anchor 的相似度會很大,因此損失函數將會變大 (分母變小),所以會讓模型在進行反向傳播時,對權重進行較大的調整。
檢索指標
在微調 sentence-transformers 時最關心的指標,用來評估正確答案有沒有被排在前面。
Recall@K (召回率) — 「有沒有抓到?」
定義: 在前 $K$ 個搜尋結果中,有沒有包含正確答案?應用: 如果你的 RAG 系統會餵 5 段資料給 LLM,那麼 Recall@5 就是關鍵。只要正確答案在前 5 名內,LLM 就有機會回答正確。分數: 只有 0 或 1(對單個查詢而言)。
MRR (Mean Reciprocal Rank) — 「正確答案排第幾?」計算方式: $\frac{1}{\text{正確答案的排名}}$。
第 1 名:$1.0$ 分、第 2 名:$0.5$ 分、第 10 名:$0.1$ 分: 它對排名的落後懲罰很重。微調成功最明顯的特徵就是 MRR 顯著提升,代表模型能一眼認出正確答案並把它排在首位。
NDCG (Normalized Discounted Cumulative Gain)特點: 比 MRR 更高級,它考慮了「相關程度」。應用: 如果搜尋結果中有「極度相關」和「部分相關」的分別,NDCG 會確保極度相關的排在越前面分數越高。它是目前搜尋引擎(如 Google)最看重的指標。
RAGAS 指標:衡量整個 RAG 系統的品質
把微調後的模型放入 RAG 流程後(對應圖片中的 Lab 05),會用 RAGAS 框架來進行自動化評估:
Faithfulness (忠實度)
白話: LLM 有沒有胡說八道?
檢查: 生成的答案是否完全來自檢索到的參考資料。
Answer Relevance (回答相關性)
白話: 答非所問嗎?
檢查: 回答的內容是否真的解決了使用者最初提出的問題。
Context Precision (檢索精準度)
白話: 撈回來的資料乾淨嗎?
檢查: 檢索到的 K 段資料中,相關資料是否排在前面,還是混入了一堆雜訊。
Context Recall (檢索召回度)
白話: 撈回來的資料夠寫答案嗎?
檢查: 檢索到的內容是否包含了回答問題所需的所有事實。
分數意義:
在 RAGAS 中,每個指標(如 Faithfulness, Answer Relevance 等)都會產出一個得分:
1.0: 完美。 0.8 以上: 表現優異,具備上線水準。 0.5 以下: 存在嚴重問題(例如:模型在胡說八道,或者沒搜到正確資料)。
RAG 介紹
基本運作
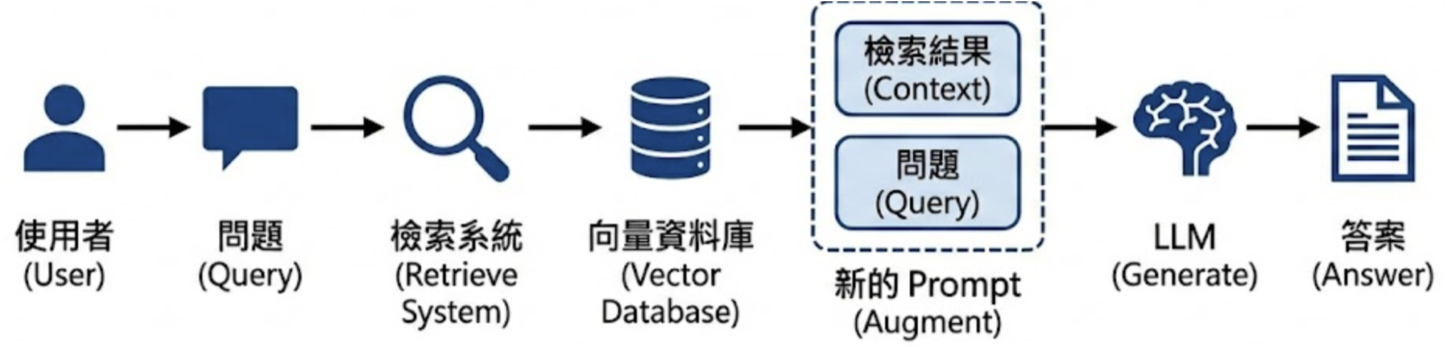
核心技術
- Embeddings 概念同上,參考上半部說明
- Vector Database 儲存向量的資料庫,因為 Vector DB 擅長模糊搜尋.相較於 SQL 可得到跟上下文較有關聯的搜尋結果
- Chunking Strategy 字數限制,以及平衡檢索精準度與上下文完整性
- Similarity Search 餘弦相似度、歐式距離、Top-K
- Prompt Template 在回答專業領域問題時,,只依賴資料庫內容回答
Vector Database
向量資料庫的選擇
| 比較項目 | ChromaDB | Weaviate | Qdrant | Milvus | pgvector | Pinecone |
|---|---|---|---|---|---|---|
| 混合搜索實作 | 應用層整合 | 內建 (BM25F) | 內建 (Sparse Vectors) | 內建 (Sparse Vectors) | SQL join | SQL join |
| Disk Support | 依賴內存 | 支援 | 強 | 強 | 依賴 Postgres Buffer | 支援 |
| MetaData Filtering | 支援 | 支援 (inverted index) | 極強 (專用 payload index) | 強 (Partition index / Scalar index) | 極強 (B-tree / GIN index) | 支援 |
| 分散式架構 | 發展中 | Sharing / Replication | Sharing / Replication | Cloud-native (Microservices) | Master-Slave / Citus | Managed |
| 適用場景 | Prototype / local LLM | 通用型,需要靈活模組 | 高效能,推薦系統,RAG | 海量數據,企業級 | 中小規模,簡化架構 | 快速上市,無維運 |
Disk support的好處 通常資料庫的大小都很大,若需要將整個資料庫掛載到記憶體內,會需要極大的記憶體空間,但通常記憶體容量是沒那麼大的。所以會需要SSD支援,運作方法是透過在記憶體的某段位址指向硬碟的資料庫,只要在進行向量比對時,記憶體內找不到資料,會藉由剛剛的地址進入SSD內搜尋,找到後將該筆向量傳回記憶體內,在記憶體進行後續計算相似度等步驟。
突破實體記憶體限制 (Scaling)
你的 Mac mini 只有 16GB 或 32GB RAM,但你可以處理 200GB 的向量資料庫。因為系統只會把「正在比對」的那一小部分向量放在實體 RAM 裡,其他的都在 SSD 待命。
緩存管理交給作業系統 (OS Caching)
資料庫不需要自己寫複雜的邏輯去決定「誰該留、誰該踢走」。Linux 或 macOS 的核心非常擅長管理這種分頁(Paging),它會自動利用剩下的 RAM 作為緩存,讓常用的向量越跑越快。
減少資料拷貝 (Zero-copy)
資料不需要從硬碟讀到內核緩衝區,再拷貝到資料庫程式的記憶體。Mmap 讓資料直接在硬碟和記憶體之間流動,減少 CPU 負擔。
Chunking
避免「垃圾進,垃圾出 (Garbage In, Garbage Out)」的發生。
關鍵參數:Chunk Size 與 Overlap
Chunk Size (塊大小): 每個片段包含多少字。
太小(如 50 字):語意破碎,模型看不懂這段在講什麼。
太大(如 1000 字):雜訊太多,檢索出來的向量會很「模糊」,且會超過 LLM 的 Context Window。
Chunk Overlap (重疊區): 片段之間重複的部分(通常設為 Size 的 10%~20%)。
- 目的: 確保語意不被切斷。例如一句話被切成兩半,有了重疊區,這句話在兩個 Chunk 裡都能保持完整。
常見方法
Recursive Character Splitter (遞迴切分): 這是最推薦的做法。
它會先嘗試按「段落 (\n\n)」切,如果太大再按「句子 (.)」切,最後才是「空格」。
好處: 盡量保持段落的完整性。
Semantic Chunking (語意切分):
利用 Embedding 模型計算句子間的相似度,當兩句話語意轉折太大時(相似度下降),才在那裡切一刀。
好處: 確保每個 Chunk 只講「一件事」。 壞處: 必須每一句都 embedding,然後一句一句比對,耗資源。
Index 索引
- HNSW
核心定義:階層式社交網路
HNSW 是一種將向量點連成「圖 (Graph)」的索引技術,利用「六度分隔理論」實現極速搜尋。
分層結構 (Hierarchical): 頂層點稀疏(高速公路),底層點密集(地方街道)。
搜尋邏輯: 從頂層「大跳躍」快速定位區域,再到底層「小碎步」精確尋找。
儲存架構:索引與數據分離
索引圖 (Graph Index): 儲存在 RAM 中(或透過 Mmap 映射)。只存點的 ID 與「鄰居清單」(誰連誰)。
原始向量 (Vector Data): 儲存在 SSD 中。包含 768 維的原始數值,透過 Mmap 傳送門 隨用隨傳。
跨批次連線機制 (Incremental Insertion) 當新向量(批次 B)進入時,如何與舊向量(批次 A)連線?
導航: B 利用現有的「全域索引圖」進行搜尋,從頂層開始搜索,所以不需要每一個點都進行相似度比對。
比對: 搜尋過程中,系統透過 Mmap 從 SSD 抓取 A 的原始向量進入 RAM。
計算: 以 餘弦相似度 或 歐式距離 計算 B 與 A 的距離。
建立: 若距離夠近,更新全域地圖:B ↔ A 建立連線。
效能關鍵
搜尋速度: O(logn)。資料量從 1 萬增加到 100 萬,搜尋時間僅微幅增加。
記憶體優勢: 搜尋時不需要全庫掃描,僅需加載搜尋路徑上的數十個向量,對 RAM 負擔極小。
瓶頸: 建立索引時最耗資源,因為頻繁的跨批次比對會觸發大量 SSD 隨機讀取。
DiskANN
設計哲學:小記憶體跑海量數據 DiskANN 是專為「記憶體有限、硬碟(NVMe SSD)極大」的環境設計。它不像 HNSW 試圖把所有東西塞進 RAM,而是將 SSD 視為運算的核心儲存。
兩階段搜尋邏輯 這套機制讓搜尋精準且不耗記憶體:
第一階段:記憶體快篩 (In-Memory Filter)
RAM 內容: 只放「Vamana 路線圖」與「壓縮向量 (PQ 指紋)」。
動作: 在記憶體內快速比對這些極小的指紋(例如從 3000 bytes 壓成 16 bytes)。
結果: 挑出前 100 個「長得最像」的候選人。
第二階段:硬碟複賽 (On-Disk Re-ranking)
SSD 內容: 存放所有「原始精確向量」。
動作: 根據快篩 ID,啟動 MMAP 傳送門 從 SSD 抓取這 100 個原始數據。
結果: 進行最終精確比對,輸出最準確的 Top 10。
Vamana 圖演算法:更強的導航 與 HNSW 的分層圖不同,DiskANN 使用單層的 Vamana 圖:
長距離連線: 故意建立跨度大的連線,減少「跳轉次數」。
目的: 減少搜尋時開啟 SSD 傳送門 的次數,因為磁碟讀取(I/O)是最昂貴的成本。
FLAT (BRUT FORCE)
- 核心原理:地毯式搜索
暴力解 問一個問題時,它會拿著你的向量,跟資料庫裡每一筆原始向量進行餘弦相似度計算。
優點:
100% 精確: 它是唯一能保證找到「絕對第一名」的方法(因為每個都算過了)。
零建立時間: 不需要建圖,資料丟進去就能搜。
缺點:
速度極慢: 資料量一旦達到 10 萬筆以上,搜尋時間會從毫秒變成秒。
適合場景: 資料量極小(< 1 萬筆),或是在做測試,需要一個「標準答案」來對照其他索引準不準時。
- 核心原理:地毯式搜索
IVF-FLAT 為了克服 FLAT 太慢的問題,IVF (Inverted File Index) 引入了「倒排檔案」的概念。
核心原理:圖書館分類法
訓練 (Training): 它會先用 K-Means 演算法,把所有向量分成 N 個群組(Clusters),並找出每個群組的「中心點」。
搜尋 (Searching):
當問題進來時,它先去跟這 N 個中心點比對,看問題屬於哪幾個群組(假設是 A 和 B)。
關鍵: 它只去 A 和 B 群組裡面進行 FLAT 暴力比對,其他群組直接無視。
優點:
速度大幅提升: 因為你只搜尋了 1% 或 10% 的資料。
記憶體省: 比 HNSW 省很多,因為它不需要存複雜的連線圖。
缺點:
非 100% 精確: 如果正確答案剛好在群組邊界,而你沒搜到那個群組,就會漏掉。
需要訓練: 每次加入大量新資料後,可能需要重新訓練中心點。